AI-Generated Images for Representing Individuals: Navigating the Thin Line between Care and Bias
@inproceedings{ahrend2025ai,
author = {Julia C. Ahrend and Björn Döge and Tom M. Duscher and Dario Rodighiero},
title = {AI-Generated Images for Representing Individuals: Navigating the Thin Line between Care and Bias},
booktitle = {IEEE VIS Arts Program (VISAP)},
year = {2025},
doi = {10.48550/arXiv.2509.03071}
}
This research discusses the figurative tensions that arise when using portraits to represent individuals behind a dataset. In the broader effort to communicate European data related to depression, the Kiel Science Communication Network (KielSCN) team attempted to engage a wider audience by combining interactive data graphics with AI-generated images of people. This article examines the project’s decisions and results, reflecting on the reaction from the audience when information design incorporates figurative representations of individuals within the data.
Introduction
Using generative AI to visualize parts of a statistical dataset highlights the tension between technical innovation and ethical responsibility. This is especially true when representing individuals or members of a specific community. It is difficult to create images that reflect the full human diversity of the data (Rodighiero 2021). For instance, models such as Midjourney 5.2 struggle to produce images that accurately depict individuals with distinct personal characteristics, such as older age and ethnicity beyond dominant Western visual norms.
These limitations are not purely algorithmic. Any act of visual representation, including those made by designers, carries aesthetic assumptions and care. This is particularly relevant in the context of a mental health project, because depression is still socially stigmatized and often depicted in dark, melancholic imagery.
To explore alternative approaches, the research team conducted a participatory workshop where participants generated their own image prompts to represent depression. The variety of results challenged prevailing visual norms and highlighted how closely representation, bias, and identification are intertwined. In this context, designing with care means not only refining prompts, but also critically engaging with the social meanings that images carry and how they shape public perception.
Background of the Project
This project was part of an explorative design study, developed in collaboration between the KielSCN and the German science magazine Spektrum der Wissenschaft. The study examined how Midjourney could enable new approaches to visualizing statistical data on mental health, as depicted in Figure 1 (Hombach 2024). The resulting imagery was featured in an interview titled “Depression. The Long Shadow of Society” (Hombach 2024).

The visualization draws on epidemiological data collected through the European Health Interview Survey (EHIS). This survey provides insights into the prevalence of depression across demographic groups in Europe (Eurostat 2021). Prevalence refers to the total number of cases of the disease in the population under consideration. Participants of the study indicated whether they had suffered from depression within the previous 12 months, or whether they experienced symptoms of the illness.
In terms of interaction, users can filter the dataset by age, gender, and country of origin. The background image adapts to these filters, allowing users to compare their demographic data with broader statistical patterns. This personalization fosters an intimate and relatable engagement with the subject of depression, one of the central objectives of the project.
In addition, the project aimed to enrich the data visualization with illustrative elements to convey the mood associated with depression by integrating images that represent individuals from the dataset. One underlying idea was that viewers may relate more strongly to personalized visualizations, potentially identifying figures reflecting their own demographic profile.
However, translating data into images introduced both technical and ethical challenges. As the project unfolded, it became clear that Midjourney’s generative model 5.2 reproduces narrow aesthetic defaults and often struggles to depict diverse populations with nuance. This raised critical questions about what it means to care, represent, and generalize in the context of visual science communication.
Interactivity: From Explanation to Exploration
In order to accommodate small screen sizes, the interface design is responsive. In the desktop version as illustrated in Figure 2, the bar chart itself functions as the filter mechanism, providing an integrated and exploratory interface (Hombach 2024). Users have the ability to directly interact with the bar charts in order to adjust parameters, thereby integrating the processes of data exploration and interaction. Conversely, the mobile version as shown in Figure 3 utilizes conventional drop-down filters, emphasizing usability and clarity on smaller screens where displaying the complete dataset is impractical (Hombach 2024). Here, emphasis is placed on percentage values that summarize the user’s selected demographic configuration.
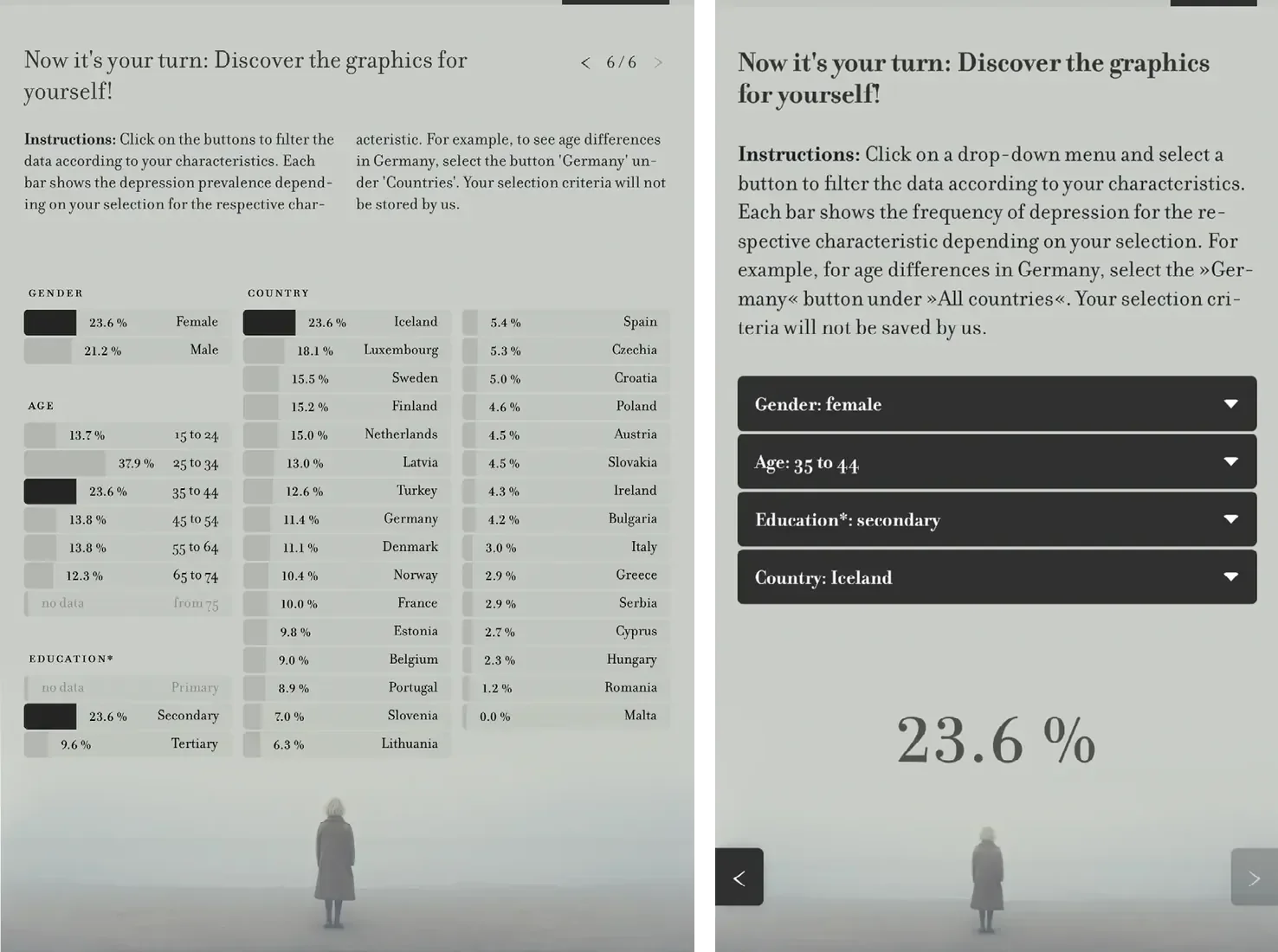
The project incorporates a second entry point in the form of a step-by-step introduction that leads users through the available filters and gradually enhances their comprehension. This structured interaction ends in the prompt to “filter data according to your characteristics,” encouraging users to reflect on how their own identity relates to the data. The complete scaffold is illustrated in Figures 4–7 (Hombach 2024). These figures underscore the disparities in visual complexity between the desktop and mobile versions.
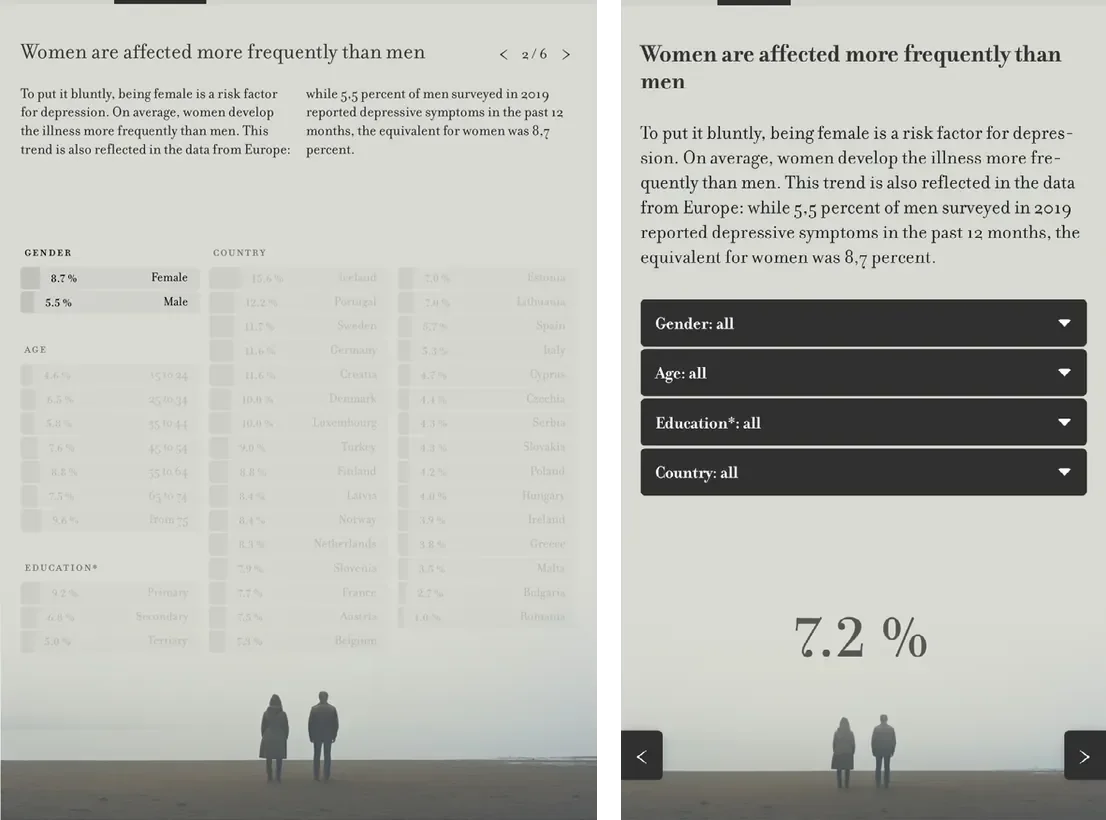
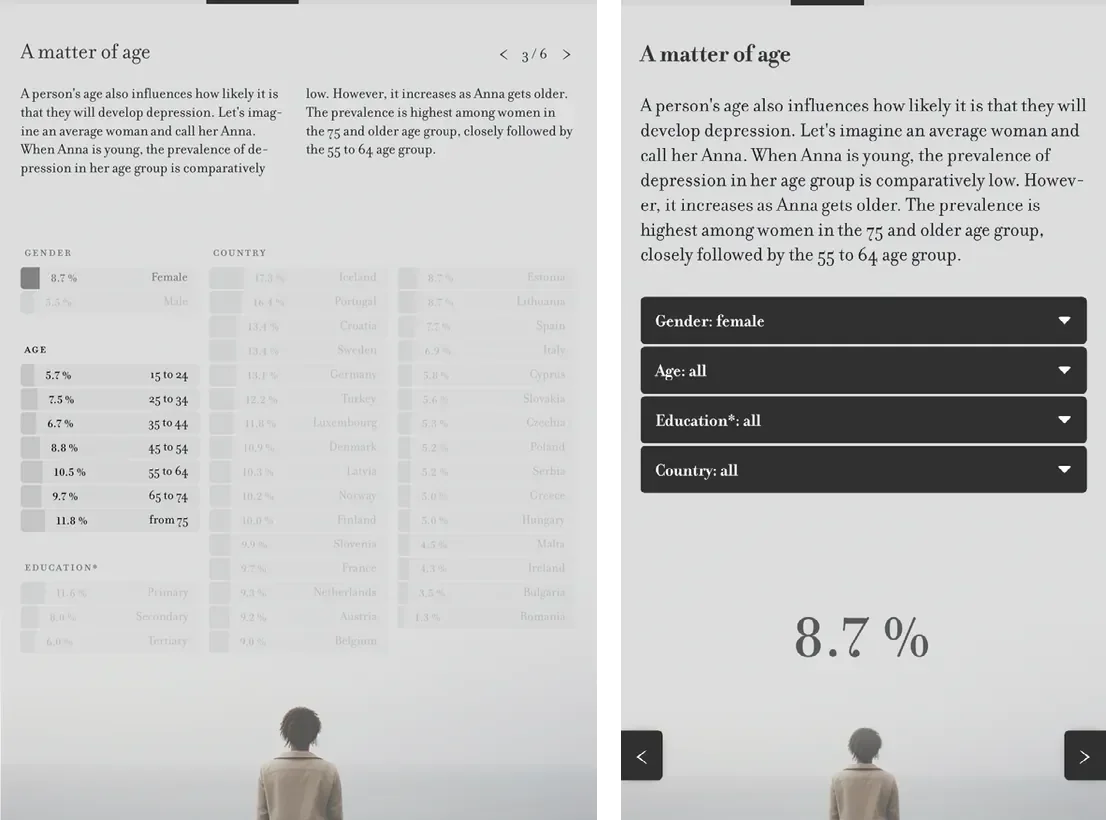
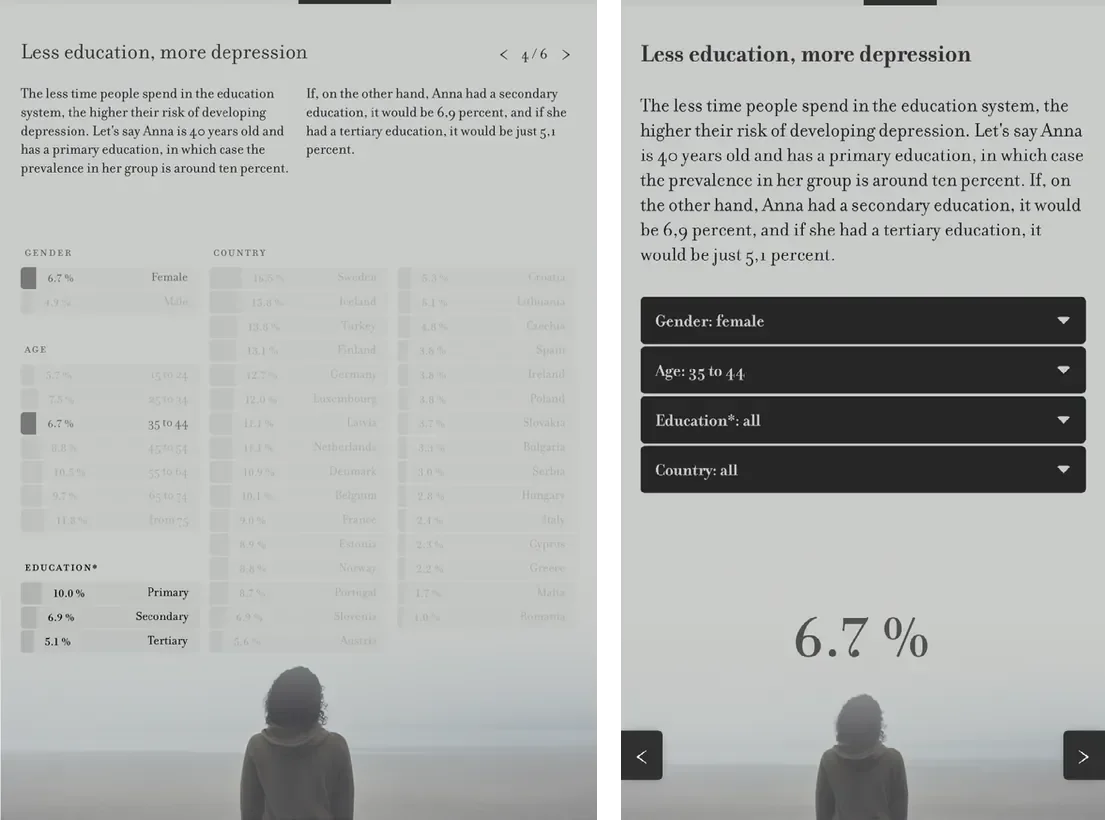
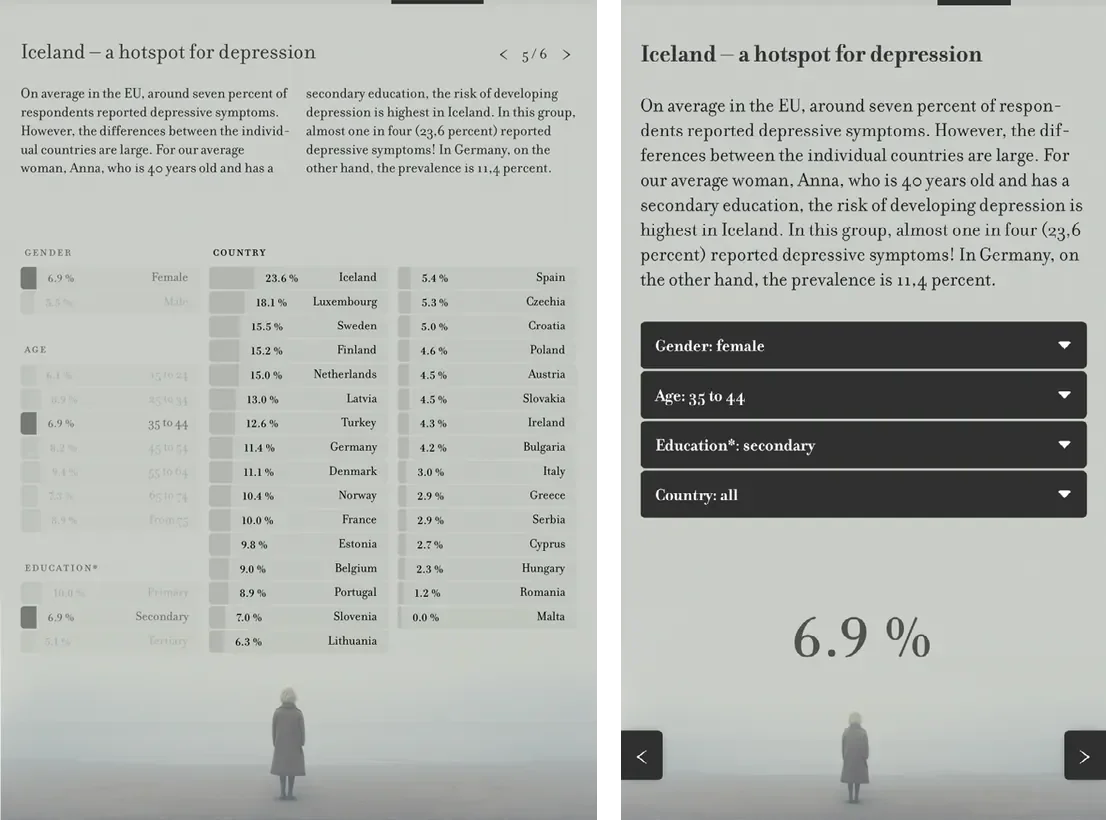
While the project team has gathered preliminary insights using Google Analytics and heatmaps, a full evaluation has not yet been conducted. Such an evaluation would be necessary to better understand what specifically guided user engagement and how the interactive elements were experienced. However, the existing data showed that users did engage with the graph: one proportion proceeded through the step-by-step introduction. A comparison with other articles on Spektrum der Wissenschaft reveals that the interaction rate was above average (1 minute 57 seconds versus 43 seconds for comparable non-interactive articles), suggesting that the interactive format may have increased user engagement.
Ethical Care: One Person as a Stand-in for a Group
One challenge for designers of data visualizations in public science communication is to capture and sustain attention, particularly when dealing with statistical content. Research by Villanueva et al. (2024) suggests that conventional formats, like bar charts, are often perceived as less engaging by non-expert audiences. Franconeri et al. (2021) further explore the interplay of engagement and information visualization tailoring. In today’s digital media landscape, visual representations of science must compete with the aesthetic norms of online platforms, where photography dominates and familiarity with images plays a key role in viewer engagement.
News media coverage of depression, for instance, frequently relies on photographic imagery depicting individuals in everyday settings, as Wang (2020) illustrates, providing a sense of intimacy and humanizing the otherwise abstract topic of depression. These images typically portray one person as a representative of a broader group of those affected. Generative AI introduces a novel possibility for visualizing data: the capacity to produce multiple, demographically varied portraits that represent different segments of a dataset.
This strategy holds particular promise for enhancing perceived relevance in public science communication. When viewers recognize individuals who resemble themselves – whether in terms of age, gender, or other socio-demographic attributes – they may feel a connection to the data being presented. This idea is explored by Rodighiero and Cellard (2019), who examine how self-recognition operates in the context of data visualization, particularly when individuals identify their own digital traces in visual representations. The phenomenon can also be further understood through the lens of Social Identity Theory, as developed by Tajfel and Turner (2019), which posits that individuals construct their self-concept partly through identification with social groups. The distinction between in-groups and out-groups influences perception, empathy, and trust. By visualizing statistical data through representations reflecting diverse group identities, designers may foster stronger identification with the subject matter – potentially increasing the salience of the information.
One approach explored in the project involved generating portraits based on biometric proxy data (age, gender, and educational background). While this technique allows for demographic tailoring, it also reveals the persistent gap between statistical categories and lived experiences. For instance, not all women aged 45–54 with tertiary education look alike, nor can any single image truly represent every individual of a group. Nevertheless, such visual approximations may offer a way to make data feel more personally meaningful, while foregrounding the tension between representation and specificity in public science communication.
After the initial experiments, the team observed that images with more realistic, front-facing portraits, such as those seen in Figures 8–11, appeared too specific, suggesting individual stories rather than representing a collective. To emphasize that each image represented a broader demographic group instead of a specific individual, the team experimented with different compositional choices.

Technical Care: Prompt Engineering
Working with Midjourney 5.2 to visualize demographic diversity quickly revealed both technical and cultural limitations. Midjourney is a text-to-image model based on diffusion techniques that generate high-resolution, stylized images through iterative prompt engineering (Midjourney 2023). While the model reliably produced images of young, slim, light-skinned individuals – particularly women – generating more varied representations required extensive prompt refinement. Older individuals, people of color, and non-normative body types were often rendered inaccurately or not at all (see Figures 12–14). For example, prompts such as “African” produced light-skinned figures unless supplemented with descriptors like “African American, ultra-short hair, dark skin, feminine” (see Figure 14). These challenges are reflected not only in the architecture of the AI model, but also in the biases embedded in the vast corpus of training images – biases that mirror the visual norms of dominant online media, where people of color often remain underrepresented, as for example highlighted by Massie et al. (2019). This insight underscores an important point: the limitations of AI-generated representation are not solely a technical issue, but a reflection of broader cultural asymmetries in the visual data produced and circulated.



As images were generated in batches, the prompts – as illustrated in Figures 12–15 – followed a consistent structure. Initially, gender was designated as a variable. Secondly, rather than utilizing numerical age values such as 15 to 24 years from the dataset, we employed descriptive language such as “teenager,” as Midjourney responded more accurately to natural language formulations. Thirdly, educational attainment was encoded through clothing descriptors. The use of “casual” dress was employed to denote primary education, “mature” attire was used to signify secondary education, and “academic” clothing was used to represent tertiary education. A “neutral” style was employed in the absence of an educational filter. However, these choices were not entirely objective; the mapping of educational levels to clothing styles inevitably entailed the application of stereotypical associations. For instance, it was assumed that individuals with lower levels of formal education would dress more informally than those with higher academic attainment.
During the prompt development phase, a paucity of diversity in the outputs was also observed. The phenomenon described above manifested in a manner that extended beyond the ethnic underrepresentation illustrated in Figures 12–14. It also encompassed individuals of advanced age. The term “elderly” frequently failed to produce convincingly aged appearances. In an effort to elicit the generation of imagery depicting individuals of advanced age, we opted for a more precise approach by employing specific descriptors such as “octogenarian” and “nonagenarian.” However, these initial prompts still proved to be inadequate. To enhance the effectiveness of the study prompts, we employed additional visual cues, such as “sitting on a bench, aged, diminutive, white hair, stooped, frail,” with the objective of eliciting more precise representations of advanced age (see Figure 15).

The last part of the prompt consisted of a description of scenery and atmosphere. For this part a key design shift emerged with the use of a compositional strategy drawn from Caspar David Friedrich’s Rückenfigur – a motif in which the subject is shown from behind. This visual distance encouraged viewers to see the figure not as a specific individual, but as a representative of a broader group. Informed by visual narrative theory and cinematic conventions, this perspective invited a more projective mode of engagement (Gschwendtner 2018).

To shape the atmosphere of the images, we aligned the visual concept with the metaphor of depression as a confrontation with the unknown, which developed to be represented by a vague, mist-laden landscape (see experiments in Figures 20 and 21). We drew inspiration from the work of cinematographer Roger Deakins, whose visual style we explicitly referenced in the image prompts, as can be seen in Figures 22–26. Deakins is known for using lighting and environment to evoke internal struggle without prescribing fixed emotional states, as analyzed by Navas and Rubio (2020). After experimentation with stylistic modifiers, the use of “cinematic Deakins style” produced an evocative yet restrained tone that harmonized with the subject matter.






However, this prompt choice was not unproblematic: referencing a visual style shaped by a white, male cinematographer within Western mainstream cinema may risk reproducing aesthetic biases encoded in that tradition through image generation. As with all design choices, prompt engineering involves visual assumptions that merit critical scrutiny.
To ensure stylistic consistency across the dataset, the refined prompt served to train Midjourney’s Style Tuner (version 5). From 128 generated style variations, the team selected the ones most aligned with the communicative goals of the project.

Although the project did not explicitly aim to critique Western visual norms, we acknowledge in this reflection on our visual style that our design decisions have certainly been informed by our backgrounds as designers and researchers shaped by European contexts, from prompt formulation to image selection.
Visualizing the Topic of Depression – Between Atmosphere and Cliché
In developing the background imagery for the interactive bar chart, the team faced a dual challenge: how to visually evoke the topic of depression without falling into reductive motifs, and how to design within the technical constraints of a dynamic, horizontally oriented layout. The composition needed to be visually calm and structurally unobtrusive, allowing space for the chart itself while still pointing toward the theme. While the chosen aesthetic aligned with our aim to convey introspection and ambiguity, it also echoed a familiar visual language often used to depict depression: gray tones, solitude, and a sense of melancholy. These stylistic choices, while legible and emotionally restrained, risked reinforcing dominant visual clichés which may overlook the full spectrum of depressive experience.
This tension highlights a central concern of designing with visual care: how to offer visual cues without reducing complex, socially stigmatized conditions to static symbols. In future iterations, a key question will be how to balance atmosphere with visibility – ensuring the image is not so subtle that users overlook it, while also avoiding excessive direction or distraction. Audience feedback from early presentations suggests that the image changes were often too inconspicuous to register. Understanding how image salience interacts with attention, perception, and interpretation remains an open question for further investigation.
Participatory Workshop: Prompting Depression, Together
To address stereotypical visual imagery associated with depression, a participatory workshop was organized. While the invitation was extended to all Spektrum der Wissenschaft subscribers, the workshop was attended by 11 women, mostly over 40 with academic backgrounds. Participants were invited to generate their own Midjourney prompts and discuss the visual language surrounding depression. The workshop revealed a broader spectrum of associations: several participants created bright, open, or emotionally ambivalent scenes (see e.g. Figures 30, 34, and 35), challenging the project’s initial low-key aesthetic. These co-created images emphasized that depression has many faces, some visible and others more subtle.



Participants voiced concern that consistent use of dark imagery may reinforce narrow, stereotypical conceptions of mental health. At the same time, discussions emerged about the risk of downplaying the condition: images perceived as overly light-hearted or serene – such as the cheerful breakfast scene seen in Figure 30 – were considered potentially misleading or dismissive of the severity of depression.
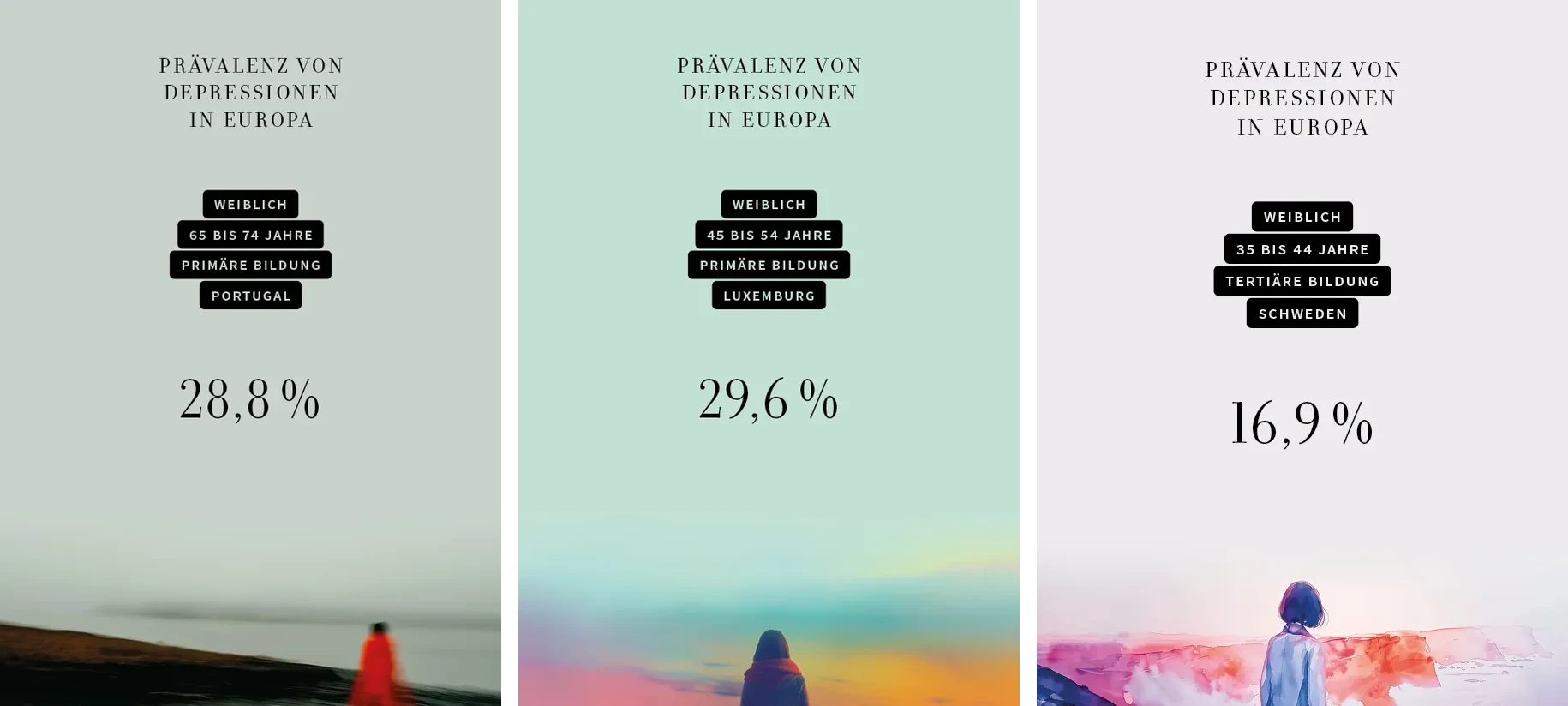
In response, the designer refined the visual concept through iteration, experimenting with new stylistic directions. The resulting postcard series (see Figures 36–38), displayed at a follow-up event, allowed for informal feedback: the watercolor-style version was most frequently taken by visitors, indicating broader resonance and an openness to more diverse visual interpretations.
Conclusion – Care as Visual Method
This project set out to explore how generative AI might help audiences see “the people behind the data” – but along the way, it revealed how easily technical convenience can reinforce normative visualities. What began as an attempt to humanize statistical prevalence data evolved into a deeper investigation of what it means to design with care in the stigmatized and socially sensitive context of depression.
Throughout the process, it became clear that neither generative models nor their outputs are neutral. From prompt design to aesthetic framing, every decision shapes how mental health is represented – or neglected. Our workshop findings highlighted both the limits of our initial visual language and the potential for more diverse and resonant interpretations. In this sense, care is not a static value but a method: iterative, dialogic, and open to critique.
As science communicators and designers working with AI, we must be vigilant not only about the images we generate but also the assumptions we carry. Navigating the line between care and bias means acknowledging that representation always involves a choice – and that thoughtful, participatory design can challenge default modes of seeing.
References
- Eurostat. 2021. “Persons Reporting a Chronic Disease, by Disease, Sex, Age and Educational Attainment Level.” https://ec.europa.eu/eurostat/databrowser/view/hlth_ehis_cd1e/default/table?lang=en
- Franconeri, Steven L., Lace M. Padilla, Priti Shah, Jeffrey M. Zacks, and Jessica Hullman. 2021. “The Science of Visual Data Communication: What Works.” Psychological Science in the Public Interest 22, no. 3: 110–161. https://doi.org/10.1177/15291006211051956
- Gschwendtner, Andrea. 2018. “Analyse der Filmmontage.” In Die Entschlüsselung der Bilder – Methoden zur Erforschung visueller Kommunikation. Ein Handbuch, 2nd ed., edited by Tanja Petersen and Christoph Schwender, 127–143. Köln: Herbert von Halem Verlag.
- Hombach, Stella Marie. 2024. “Depression: Fördert unsere Gesellschaft psychische Erkrankungen?” Spektrum der Wissenschaft. https://www.spektrum.de/angebote/visuelle-wissenschaftskommunikation/depression-foerdert-unsere-gesellschaft-psychische-erkrankungen/2200836
- Massie, Jennifer P., Danny Y. Cho, Christina J. Kneib, Joshua R. Burns, Courtney S. Crowe, Megan Lane, Amira Shakir, David L. Sobol, Jason Sabin, João D. Sousa, Eduardo D. Rodriguez, Travis Satterwhite, and Scott D. Morrison. 2019. “Patient Representation in Medical Literature: Are We Appropriately Depicting Diversity?” Plastic and Reconstructive Surgery – Global Open 7, no. 12: e2563. https://doi.org/10.1097/GOX.0000000000002563
- Midjourney. 2023. “Legacy Features.” https://docs.midjourney.com/hc/en-us/articles/33329788681101-Legacy-Features
- Navas, Ana Isabel C., and Sara G. Rubio. 2020. “Study on the Cinematographic Image Composition: Frame, Light, and Colour as Expressive Elements in Roger Deakins’s Work.” Doxa Comunicación 31: 207–238. https://doi.org/10.31921/doxacom.n31a10
- Rodighiero, Dario. 2021. Mapping Affinities: Democratizing Data Visualization. Geneva: MétisPresses. https://www.metispresses.ch/en/mapping-affinities
- Rodighiero, Dario, and Loup Cellard. 2019. “Self-Recognition in Data Visualization: How Individuals See Themselves in Visual Representations.” EspacesTemps.net: Electronic Journal of Humanities and Social Sciences, August. https://doi.org/10.26151/espacestemps.net-wztp-cc46
- Tajfel, Henri, and John C. Turner. 2019. “The Social Identity Theory of Intergroup Behavior.” In Political Psychology. https://doi.org/10.4324/9780203505984-16
- Villanueva, Iris I., Naomi Li, Thomas Jilk, Julia Renner, Bradley R. van Matre, and Dominique Brossard. 2024. “When Science Meets Art on Instagram: Examining the Effects of Visual Art on Emotions, Interest, and Social Media Engagement.” Science Communication 46, no. 2: 210–238. https://doi.org/10.1177/10755470241228279
- Wang, Wen. 2020. “Exemplification and Stigmatization of the Depressed: Depression as the Main Topic versus an Incidental Topic in National US News Coverage.” Health Communication 35, no. 8: 1033–1041. https://doi.org/10.1080/10410236.2019.1606874