Moving Pictures of Thought: Extracting Visual Knowledge in Charles S. Peirce’s Manuscripts with Vision-Language Models
@inproceedings{pedretti2025moving,
author = {Carlo Teo Pedretti and Davide Picca and Dario Rodighiero},
title = {Moving Pictures of Thought: Extracting Visual Knowledge in Charles S. Peirce’s Manuscripts with Vision-Language Models},
booktitle = {Anthology of Computers and the Humanities},
year = {2025},
doi = {10.63744/fkFGJ6wSzDPV}
}
Diagrams are crucial yet underexplored tools in many disciplines, demonstrating the close connection between visual representation and scholarly reasoning. However, their iconic form poses obstacles to visual studies, intermedial analysis, and text-based digital workflows. In particular, Charles S. Peirce consistently advocated the use of diagrams as essential for reasoning and explanation. His manuscripts, often combining textual content with complex visual artifacts, provide a challenging case for studying documents involving heterogeneous materials. In this preliminary study, we investigate whether Vision-Language Models (VLMs) can effectively help us identify and interpret such hybrid pages in context. First, we propose a workflow that (i) segments manuscript page layouts, (ii) reconnects each segment to IIIF-compliant annotations, and (iii) submits fragments containing diagrams to a VLM. In addition, by adopting Peirce’s semiotic framework, we designed prompts to extract key knowledge about diagrams and produce concise captions. Finally, we integrated these captions into knowledge graphs, enabling structured representations of diagrammatic content within composite sources.
Introduction
Diagrams play a central role in many forms of reasoning, from mathematics to philosophy and religious art (Hamburger 2019; Latour 1990; Rodighiero et al. 2023). Among the most prominent theorists of diagrammatic reasoning is Charles S. Peirce, who conceived of diagrams as a subtype of icon capable of representing and manipulating internal structures through visual means (Stjernfelt 2007; de Waal 2013). In his unpublished manuscripts, diagrams such as Existential Graphs illustrate logical inferences via spatial configurations, offering a visual alternative to symbolic logic. Peirce referred to these constructs as “moving pictures of thought” (Peirce 1931, CP 4.8), underlining their dynamic and epistemological function.
This idea finds material expression in Peirce’s manuscripts, where textual content, visual artifacts, and complex layouts are seamlessly integrated (Keeler 2020b). These documents reflect both his theoretical commitment to diagrammatic reasoning and its practical development through layered and visually structured writing. However, this visual richness remains largely inaccessible in existing printed editions, which are compiled under severe editorial constraints (Keeler 1998, 2020a).
Building on recent advances in the textual analysis of Peirce’s manuscript Prolegomena to an Apology for Pragmaticism (PAP) (Picca et al. 2023), we extend the investigation to his visual thinking. This exploratory study investigates the extent to which Vision-Language Models (VLMs) can engage with diagrams as operative semiotic forms. To address this question, we propose a flexible and interoperable workflow for extracting structured knowledge from multimodal documents that supports integration within Linked Open Data (LOD) environments. Our modular workflow begins with the segmentation of page layouts to isolate diagrams, which are then linked to IIIF annotations. These fragments are submitted to a VLM via prompt-based interactions informed by Peirce’s semiotic theory, with the aim of generating structured descriptions of diagrammatic content. The resulting outputs were then serialized in RDF, enabling machine-readable representations of visual reasoning within complex multimodal sources.
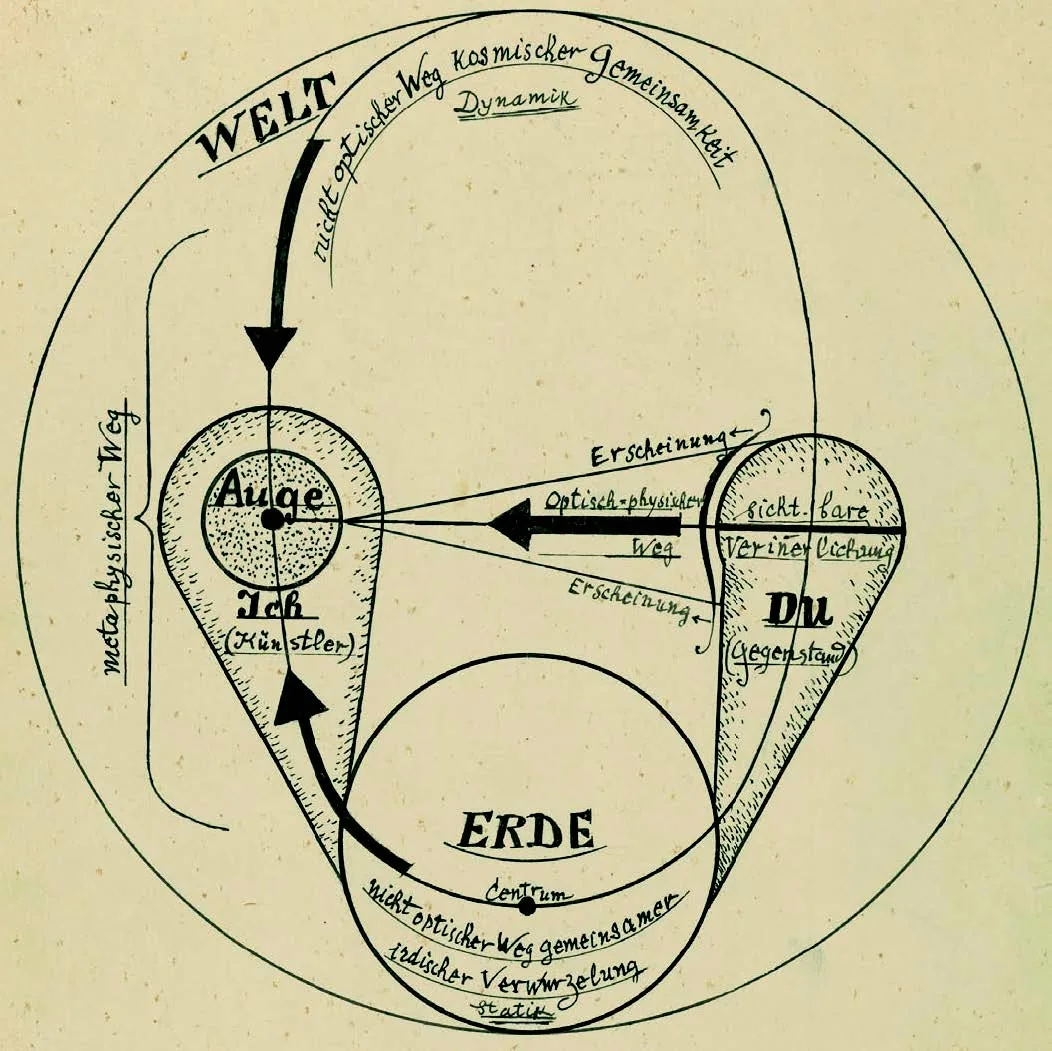
Background and Related Works
In his work, Peirce often emphasized the role of diagrams in reasoning (de Waal 2013), providing various examples of what he termed diagrammatic reasoning (CP 4.571, 5.148, 6.213). On the one hand, diagrams exhibit an iconic character: they are a specific subtype of icon capable of representing the internal structure of the objects they depict through the arrangement of their interconnected parts. For example, a map that shows historical trade routes by positioning ports and drawing connecting lines already functions as a diagram, as it represents spatial and relational structures that mirror real-world networks of movement and exchange. On the other hand, diagrams also possess a dynamic character, as they enable manipulation and iterative transformations according to the general laws governing the relationships among their parts, and as such, pose epistemological questions about the generation and production of knowledge (Kiryushchenko 2023; Stjernfelt 2007). For instance, a simple triangle drawn on paper can serve as a diagram of all triangles by altering its angles or side lengths while preserving its topology. Most notably, Peirce developed a system of visual logic known as Existential Graphs, structured into four levels: Alpha for propositional logic, Beta for modal and higher-order logic, and Gamma and Delta for meta-assertions and non-declarative statements. Existential Graphs use visual connectors such as lines, curves, and nodes to represent logical relations. To start, the Sheet of Assertion is a blank space on which diagrams are drawn. Any proposition written directly on it is considered to be asserted as true. A continuous line connecting the elements indicates a logical identity. Enclosures, such as closed curves, represent negation; therefore, a region inside a curve is logically negated. Juxtaposed elements without connectors are logically conjunctive (i.e., both are assumed to be true). A bifurcation indicates a logical disjunction. These characteristics make Peirce’s diagrams interesting for computational modeling; however, their formal and visual complexity also requires methods capable of isolating and structuring heterogeneous visual content within manuscripts.

The structural heterogeneity of historical manuscripts poses significant challenges for automated information extraction and semantic indexing. Recent studies have developed machine learning pipelines for layout segmentation, targeting both textual and non-textual elements, such as illuminations and decorative initials (Aouinti et al. 2022; Büttner et al. 2022). Object detection models, such as YOLO (Yaseen 2024), have also been employed to identify image regions in complex manuscript layouts, offering effective layout segmentation (Ravichandra, Sathya, and Sophie 2022). Among these approaches, Fleischhacker, Göderle, and Kern (2025) proposed a pipeline that combines layout detection, synthetic data augmentation, OCR fine-tuning, and reintegration of outputs as IIIF-compliant annotations. While such methods enable the scalable processing of visually rich documents, they do not incorporate mechanisms for semantic enrichment or integration into LOD frameworks. To address this issue, ontological extensions of the Web Annotation Data Model (WADM) (Sanderson, Ciccarese, and Young 2017) have been proposed. The Multi-Level Annotation Ontology (MLAO) (Pedretti et al. 2024) introduces conceptual anchoring and provenance for annotations, while the General Ekphrastic Ontology (GEkO) (Bocchi, Pedretti, and Vitali 2025) models ekphrastic relations between textual descriptions and visual elements. These limitations also highlight the need for approaches that combine visual segmentation with semantic interpretation. In this context, VLMs represent promising tools for bridging the gap between image analysis and knowledge extraction processes.
In recent years, the intersection of computer vision and art history has seen a growing integration of visual and textual modalities, driven by the availability of large art collections of digitized images and the development of multimodal machine learning techniques. This has led to substantial interest in tasks such as visual link retrieval, multimodal classification, iconographic captioning (Cetinic 2021), and visual question answering (VQA) (Garcia and Vogiatzis 2019), particularly in domains such as cultural heritage, where image content is often accompanied by curatorial or scholarly metadata. Although multimodal models can describe visual elements, they often struggle to understand the logical or spatial relationships among them. This limitation has been highlighted in recent studies that show how VLMs tend to rely on background knowledge rather than analyzing the internal structure of diagrams (Hou et al. 2024). To overcome this, some approaches combine image segmentation and structured prompting. For example, the chain-of-regions method decomposes diagrams into meaningful areas before interpreting them, improving the model’s reasoning about spatial relations (Zhang et al. 2024). Other studies have applied VLMs to structured visual domains, such as UML diagrams or flowcharts, using modular reasoning pipelines to achieve more accurate results (Liang et al. 2024). However, to the best of the authors’ knowledge, no existing study has specifically addressed the use of VLMs for identifying or interpreting diagrammatic content in historical sources. In this context, applying similar strategies to Peirce’s existential graphs means using layout segmentation to isolate diagram regions and then prompting VLMs with questions informed by Peirce’s semiotics. This structured workflow helps models provide more accurate interpretations of diagrammatic reasoning.
Methods
Corpus Description and Preprocessing
The Charles S. Peirce Papers (MS Am 1632) (Robin 1971), housed at Harvard’s Houghton Library, represent one of the most extensive archival collections of Peirce’s works. Comprising over 1,700 manuscript items, the collection spans disciplines ranging from mathematics to logic and metaphysics. A subset of 233 items was digitized and made available through IIIF Manifests via the Harvard Hollis system (Harvard University 2023), yielding a total of 15,695 high-resolution facsimile images.
To prepare the corpus for computational processing, we retrieved IIIF metadata for each digitized item, including canvas structure, image URIs, and classification labels derived from Robin’s catalogue (Robin 1971). All canvases were downloaded at full resolution and organized into thematic folders. Blank pages, identified using IIIF metadata, were automatically excluded, resulting in a set of 13,234 manuscript pages (Table 1).
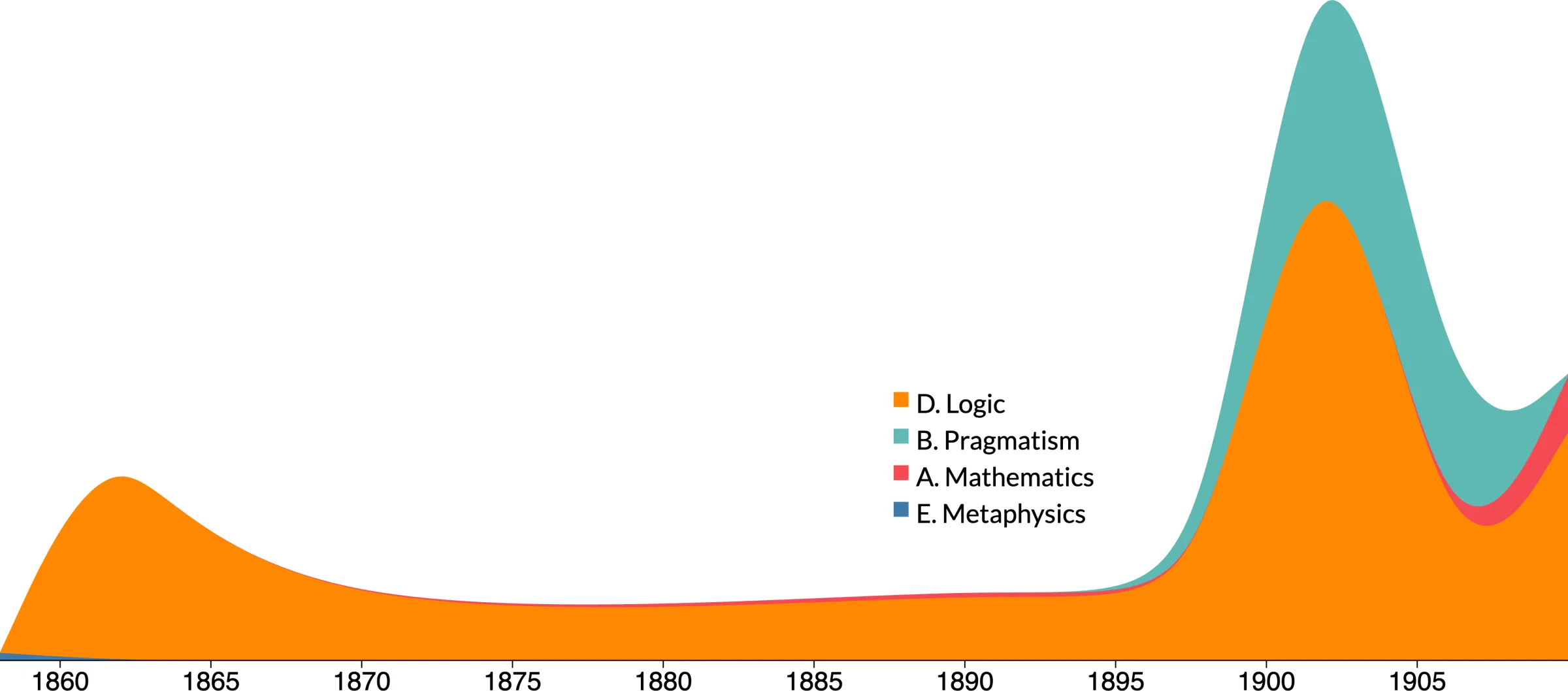
To contextualize the corpus thematically, we constructed a bump chart showing the distribution of digitized pages in Robin’s topical categories grouped by five-year intervals within Peirce’s lifetime (Figure 3). Category D (Logic) dominates the corpus, followed by Pragmatism (B) and Metaphysics (E), reflecting Peirce’s focus on formal reasoning and motivating our attention to visual content in these areas.
| Description | Count |
|---|---|
| Total manuscript items | 1,759 |
| Digitized items | 233 |
| Total digitized pages | 15,695 |
| Blank pages removed | 2,461 |
| Pages retained for processing | 13,234 |
Models for Page and Layout Analysis
To distinguish textual from visually mixed pages, we implemented a classification pipeline based on three feature extraction strategies: Histogram of Oriented Gradients (HOG), intermediate features from ResNet18, and semantic embeddings from the CLIP visual encoder. Each page was labeled as either text (pages containing mostly textual elements), diagram_mixed (pages containing at least one relevant visual feature), or cover using a manually annotated dataset of 1,264 pages.
To extract diagrammatic content from the classified diagram_mixed pages, we created a manually annotated dataset of 443 manuscript images. Each page was labeled using a two-class schema: diagram and text_block. This typology was designed to identify the main visual and textual regions while preserving the layout-level structure and supporting generalization across diverse manuscript formats. At this stage, we intentionally avoided adding more granular annotations, such as dates, titles, sketches, logical notation, or algebraic formulas, to prevent class imbalances in the training data.
The dataset was split into training and validation subsets using an 80/20 ratio. To address the class imbalance and increase robustness, we applied data augmentation to all pages containing at least one diagram annotation. Two synthetic variants were generated for each page, resulting in a final training set of 1,133 images. Finally, we fine-tuned the YOLOv8m model on this dataset, which was selected for its balance between detection performance and computational efficiency.
Annotation Workflow
All detected segments, whether diagrams or text blocks, were transformed into structured annotations compliant with the IIIF. Each segment is expressed as an instance of WADM, linking a specific region of the manuscript image (the target) to a content resource or metadata element (the body), serialized in JSON-LD format. Bounding boxes are mapped to IIIF Canvas coordinates using the xywh fragment selector, ensuring the precise anchoring of visual elements within the page layout.
To enhance semantic expressiveness, we employ MLAO (Pedretti et al. 2024), an extension of WADM. The MLAO introduces the mlao:Anchor class to separate the annotated physical region from its conceptual referent. In our use case, anchors are linked to the IIIF URI of the full manuscript page via mlao:isAnchoredTo, enabling a shared conceptual reference for both textual and diagrammatic segments of the manuscript. Instead of predefined abstraction layers (e.g., Work, Expression, Manifestation, and Item according to LRMoo (Riva, Žumer, and Aalberg 2022)), we define custom conceptual categories based on Peirce’s semiotic theory (see below). Interpretative captions generated by the VLM are modeled as oa:TextualBody instances linked to a hico:InterpretationAct (Daquino and Tomasi 2015) that specifies the interpretative level, model used, and generation process via PROV-O. This structure supports the hermeneutic traceability and versioning of automated interpretations.
Annotations are generated from the detection outputs and can be embedded in IIIF Manifests or published as standalone pages. Annotations can also be serialized in RDF for semantic querying. This semantic layer supports integration into LOD workflows and prepares the content for VLM interpretation and use.
VLM Prompting and Interpretation
Peirce’s semiotic theory offers a framework to understand the structure and function of signs, which we use as a basis to design VLM prompts. We define three analytical categories for prompt engineering that operationalize aspects of Peirce’s semiotic theory for computational analysis. These categories are designed for VLM prompting rather than direct applications of his icon-index-symbol trichotomy. The morphological level addresses the basic visual elements that constitute a diagram, such as lines, shapes, and symbols. This corresponds broadly to the iconic mode of representation and relates to Peirce’s category of Firstness. The indexical level concerns the relationships between these elements, identifying connections, dependencies, or structural links. This reflects aspects of Peirce’s notion of Secondness. The symbolic level explores the logical operations encoded in the diagram. At this stage, we provide the VLM with minimal instructions on how to interpret visual conventions (e.g., enclosure, juxtaposition, lines of identity), prompting the model to reconstruct the inferential logic underlying the structure. This aligns with Peirce’s category of Thirdness. Table 2 shows the specific question templates for each category.
Finally, we defined three classes extending the MLAO data model (pip:MorphologicalLevel, pip:IndexicalLevel, and pip:SymbolicLevel) to represent the semiotic categories described earlier. The VLM-generated responses, along with metadata about the model and prompt, were re-injected as annotations into the IIIF-compliant JSON-LD structure. Each annotation targets a specific region of the IIIF canvas and references the full manuscript page via its persistent URI.
| Semiotic Level | Question Template |
|---|---|
| Morphological | How many and what kind of elements (e.g., words, lines, arcs, nodes, shapes, etc.) are present in the image? |
| Indexical | Is there a relationship between the elements present in the image? Which elements are connected to each other? |
| Symbolic | In Peirce’s diagrammatic logic, a closed curve called a cut represents logical negation. Elements inside the same region are interpreted conjunctively (i.e., asserted together). Elements placed directly on the background (the Sheet of Assertion) are considered true. A cut around propositions denies them. Nested cuts represent nested negation. Lines may indicate identity or existential quantification. Based on these principles, interpret the diagram and translate its meaning into a logical statement. If this is not possible, provide a clear explanation in natural language. |
Evaluation Methodology
To assess the interpretative capabilities of VLMs with respect to Peirce’s diagrammatic logic, we conducted a qualitative evaluation across five diagrams of increasing complexity, manually selected from the Peirce manuscript corpus and belonging to the Alpha level. Standard reference-based metrics, such as CLIPScore (Hessel et al. 2021), are limited in this context, as they primarily measure lexical similarity and do not account for the semantic or structural accuracy of a caption (Cetinic, Lipic, and Grgic 2018; D’Armenio, Deliège, and Dondero 2025). This makes them unsuitable for evaluating the descriptions of abstract and diagrammatic content. For each diagram, three structured prompts were submitted to the models, corresponding to Peirce’s semiotic categories: morphological (element enumeration), indexical (relational structure), and symbolic (logical translation), as shown in Table 2. We tested five VLMs: BLIP3-o (Chen et al. 2025), GPT-4o, LLaVA 1.6 vicuna-13b (Liu et al. 2023), MiniGPT-4 vicuna-13b (Zhu et al. 2023), and Phi-4 Multimodal (Haider et al. 2024), all of which accept both visual and textual inputs. This evaluation aimed to compare their capacity to recover structured meaning from diagrammatic forms, with particular attention to inferential depth and semiotic coherence.
Each response was rated on a 3-point scale: 2 for correct and complete answers, 1 for partially correct answers, and 0 for incorrect or irrelevant responses. The total possible score was 30 (3 questions × 5 diagrams × 2 points).
Results and Discussion
Performance of Preparatory Models
The best performance for image classification was achieved using a logistic regression classifier trained on CLIP embeddings. Using 10-fold stratified cross-validation, the model achieved a macro-averaged F1-score of 0.9531, with good class-wise accuracy across the board. The full results of the model comparison are reported in Appendix A. To assess the distribution of visual content across the corpus, we applied the trained classifier to all digitized pages and aggregated the predictions according to thematic categories. As shown in Figure 4, visual content is especially concentrated in Category D (Logic), followed by Pragmatism (B) and Metaphysics (E), suggesting that Peirce used visual reasoning more frequently in these areas.
| Class | Precision | Recall | F1 Score | Support |
|---|---|---|---|---|
| Cover (0) | 1.0000 | 1.0000 | 1.0000 | 28 |
| Text (1) | 0.9459 | 0.8974 | 0.9211 | 117 |
| Diagram (2) | 0.9040 | 0.9496 | 0.9262 | 119 |
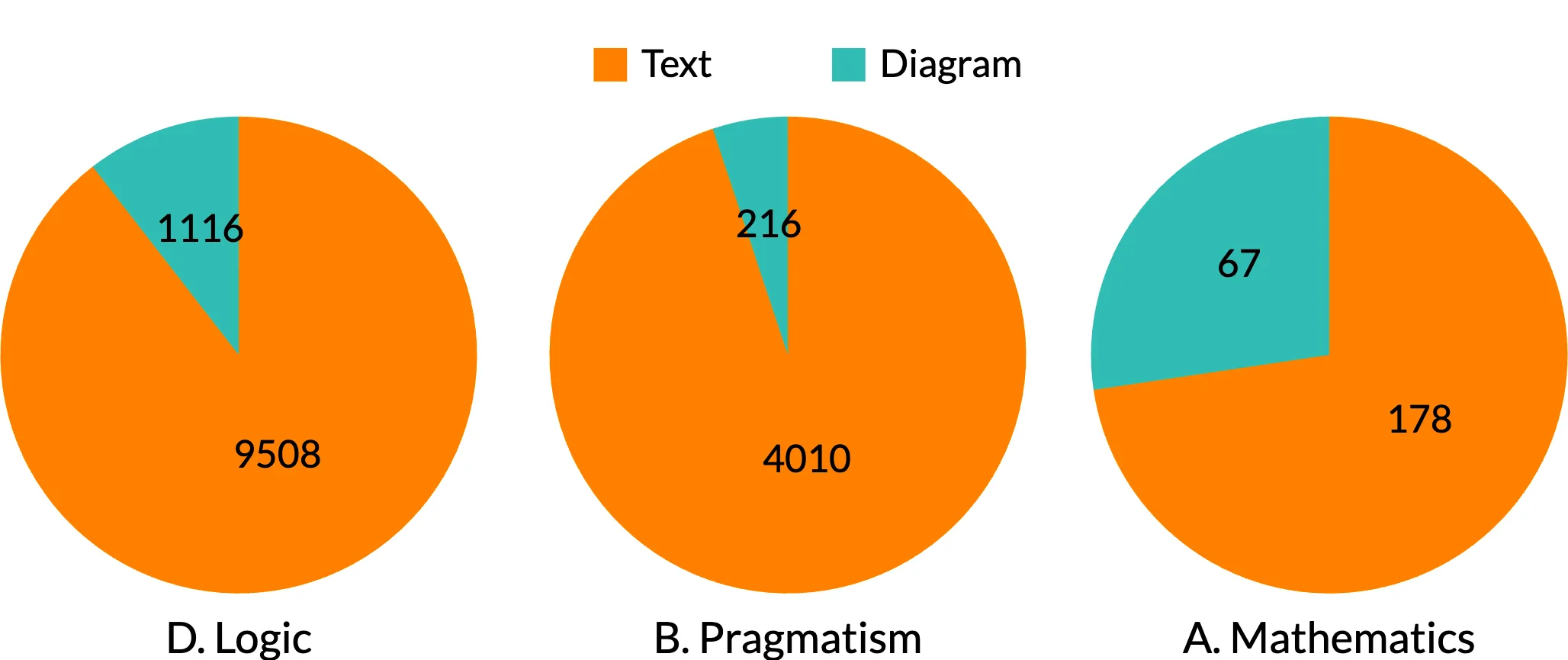
On the validation set (111 pages), the fine-tuned YOLOv8m model achieved a mean Average Precision at IoU 0.5 (mAP@0.5) of 0.981, with a class-specific score of 0.992 for diagram and 0.970 for text_block. The precision, recall, and F1 scores are reported in Table 4. A sample prediction with annotations is shown in Figure 5.1
| Metric | Diagram | Text Block | All Classes |
|---|---|---|---|
| mAP@0.5 | 0.992 | 0.970 | 0.981 |
| Precision (at best F1) | 0.990 | 0.960 | 0.975 |
| Recall (at best F1) | 1.000 | 0.940 | 0.990 |
| Optimal F1 score | 0.996 | 0.948 | 0.960 |
| Confidence @ Optimal F1 | 0.547 | 0.547 | 0.547 |
| Confidence @ Max Precision | 0.975 | 0.975 | 0.975 |
| Confusion (TP) | 684 | 473 | – |
| Confusion (FP) | 38 | 58 | – |
| Confusion (FN) | 3 | 23 | – |

Preliminary VLM Evaluation
As shown in Table 5, GPT-4o achieved the highest score (25/30), demonstrating relatively strong performance across all semiotic dimensions. BLIP3-o followed with 12/30, showing partial competence in recognizing visual elements but struggling with relational and symbolic interpretation. Phi-4 obtained a total of 6 points, with modest success in symbolic recognition but weak results in the other dimensions. Both LLaVA 1.6 and MiniGPT-4 scored 0, failing to produce meaningful responses to any of the evaluative questions.
While GPT-4o and BLIP3-o can handle layout-level tasks without fine-tuning, their performance drops significantly when confronted with more complex diagrams involving nested cuts or non-trivial spatial configurations. Some errors are attributable to OCR-like misrecognition, such as reading “wounded” as “mound” or “man” as “noun”. Across nearly all models, the symbolic level obtained the lowest average scores, with frequent failures in understanding negation correctly (e.g., misinterpreting a cut as emphasis, or ignoring it entirely) and generating logically valid formalizations (e.g., confusing ¬(A ∧ B) with ¬A ∧ ¬B), or even hallucinating logical rules (in smaller models). Interestingly, considering the diagram in Figure 6, both GPT-4o and BLIP3-o produced formal logical statements in response to the symbolic question. GPT-4o correctly generated “There exists a man who is not both wounded and disgraced,” and formalized it as:
∃x (Man(x) ∧ ¬(Wounded(x) ∧ Disgraced(x)))
BLIP3-o instead produced “It is not the case that there exists a man who is wounded and disgraced,” rendered as:
¬∃x (Man(x) ∧ Wounded(x) ∧ Disgraced(x))
This suggests that while BLIP3-o demonstrates surface-level competence in formalization, GPT-4o is better able to align visual features with underlying logical relations.
To finalize the workflow suggested at the end of the VLM prompting section, we also produced the RDF serialization of the annotations generated by the model.2
| Model | Morphological | Indexical | Symbolic | Total |
|---|---|---|---|---|
| GPT-4o | 7 | 9 | 9 | 25 |
| BLIP3-o | 3 | 5 | 4 | 12 |
| Phi-4 | 1 | 1 | 4 | 6 |
| LLaVA 1.6 | 0 | 0 | 0 | 0 |
| MiniGPT-4 | 0 | 0 | 0 | 0 |

The high concentration of diagrams in Peirce’s manuscripts offers a quantitative overview of the importance of visual representations as working instruments during reasoning itself, aligning with the philosopher’s pragmatic maxim that concepts acquire meaning through their operational use rather than from correspondence to abstract or a priori definitions. In other words, Peirce recurred to diagrammatic reasoning on paper as a privileged way to develop his arguments and to enable the manipulation of relational structures. Through this perspective, this exploratory analysis reveals Peirce’s philosophy as an embodied practice where “moving pictures of thought” and linear writing operate in a continuous exchange, underlining at the same time the importance of intermediality in such heterogeneous manuscripts, supporting the arguments raised by Keeler (2020b). Our preliminary VLM evaluation serves as a pilot study. Expanding the dataset would enable systematic investigation of how Peirce’s model of semiosis relates to how VLMs process diagrammatic content, and whether studying these models can in turn clarify what diagrammatic reasoning requires. The workflow presented here makes such evaluation feasible across the full corpus.
Conclusion
This preliminary work presents a modular pipeline for analyzing heterogeneous manuscript collections, combining layout classification, object detection, and semantic annotation within IIIF and LOD frameworks. The workflow extends WADM through MLAO and introduces a qualitative VLM evaluation method structured around analytical categories derived from Peirce’s semiotic theory. Applied to Peirce’s manuscripts, the analysis reveals that the quantitative distribution of visual reasoning is concentrated in specific philosophical domains, with Logic manuscripts containing 10.5% diagrams versus 5.1% in Pragmatism. This shows that diagrammatic practice was functionally integrated into Peirce’s work on formal systems. Second, the VLM evaluation reveals that GPT-4o can approximate logical interpretation when appropriately prompted (25/30 points), while smaller models underperform. The differential performance across morphological, indexical, and symbolic questions validates these as functionally distinct analytical operations.
The methodological pattern extends beyond Peirce studies. Any manuscript collection combining text and visual elements can adapt this workflow by substituting domain-appropriate theoretical frameworks, retraining segmentation models, and adjusting prompts to specific research questions. Moreover, the workflow can be integrated into semantic digital editions based on digital facsimiles. Textual content can be transcribed using HTR, while annotations contextualize visual elements at multiple scales. The annotations generated through this process can automatically enrich knowledge graphs. Finally, by treating annotations as digital traces of interpretation, the system aligns with Peirce’s pragmatist view of semiosis as an ongoing process.
Appendix A. Model Comparison for Page Classification
| Feature | Model | Avg Precision | Avg Recall | Avg F1 Score | Accuracy |
|---|---|---|---|---|---|
| CLIP | Linear SVM | 0.9335 | 0.9320 | 0.9321 | 0.9091 |
| CLIP | Logistic Regression | 0.9500 | 0.9490 | 0.9491 | 0.9318 |
| CLIP | Random Forest | 0.9296 | 0.9293 | 0.9294 | 0.9053 |
| CLIP | SVM RBF | 0.9500 | 0.9460 | 0.9461 | 0.9280 |
| CLIP | k-NN (k=5) | 0.9123 | 0.9093 | 0.9093 | 0.8788 |
| CNN | Linear SVM | 0.9351 | 0.9350 | 0.9350 | 0.9129 |
| CNN | Logistic Regression | 0.9356 | 0.9349 | 0.9350 | 0.9129 |
| CNN | Random Forest | 0.9183 | 0.9180 | 0.9181 | 0.8902 |
| CNN | SVM RBF | 0.9183 | 0.9180 | 0.9181 | 0.8902 |
| CNN | k-NN (k=5) | 0.8932 | 0.8835 | 0.8882 | 0.8561 |
| HOG | Linear SVM | 0.8341 | 0.8243 | 0.8290 | 0.7765 |
| HOG | Logistic Regression | 0.8361 | 0.8361 | 0.8361 | 0.7803 |
| HOG | Random Forest | 0.8688 | 0.8375 | 0.8504 | 0.8182 |
| HOG | SVM RBF | 0.8548 | 0.8351 | 0.8442 | 0.8030 |
| HOG | k-NN (k=5) | 0.6659 | 0.6974 | 0.5889 | 0.6212 |
| True / Predicted | Cover | Text | Diagram_mixed |
|---|---|---|---|
| Cover | 28 | 0 | 0 |
| Text | 0 | 105 | 12 |
| Diagram_mixed | 0 | 6 | 113 |
References
- Aouinti, Mehdi, Clément Plancq, Nicolas Froeliger, François Leclère, and Christophe Rico. 2022. “Detecting Illuminations in Digitized Medieval Manuscripts: A Benchmark Dataset and Evaluation Protocol.” Digital Medievalist 15 (1): 1–18. https://doi.org/10.16995/dm.7844
- Bocchi, Maria Francesca, Carlo Teo Pedretti, and Fabio Vitali. 2025. “Between Text and Icon: Towards a Representational Model for Ekphrastic Relations.” In Proceedings del XIV Convegno Annuale AIUCD2025, edited by Simone Rebora, Marco Rospocher, and Stefano Bazzaco, 566–572. Verona: AIUCD. https://doi.org/10.6092/UNIBO/AMSACTA/8380
- Büttner, Stefan, Tilo Wettig, Dominik König, Matthias Springer, and Roland Wittler. 2022. “CorDeep: A Deep Learning-Based Approach to the Detection and Classification of Visual Elements in Historical Documents.” Journal of Imaging 8 (10): 285–303. https://doi.org/10.3390/jimaging8100285
- Cetinic, Eva. 2021. “Towards Generating and Evaluating Iconographic Image Captions of Artworks.” Journal of Imaging 7 (8): 123. https://doi.org/10.3390/jimaging7080123
- Cetinic, Eva, Tomislav Lipic, and Sonja Grgic. 2018. “Fine-Tuning Convolutional Neural Networks for Fine Art Classification.” Expert Systems with Applications 114: 107–118.
- Chen, Jiuhai, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, et al. 2025. “BLIP3-o: A Family of Fully Open Unified Multimodal Models—Architecture, Training and Dataset.” arXiv:2505.09568. https://doi.org/10.48550/ARXIV.2505.09568
- D’Armenio, Enzo, Adrien Deliège, and Maria Giulia Dondero. 2025. “A Semiotic Methodology for Assessing the Compositional Effectiveness of Generative Text-to-Image Models (Midjourney and DALL·E).” In Lecture Notes in Computer Science, 112–127. Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-92089-9_8
- Daquino, Marilena, and Francesca Tomasi. 2015. “Historical Context Ontology (HiCO): A Conceptual Model for Describing Context Information of Cultural Heritage Objects.” In Metadata and Semantics Research, edited by Emmanouel Garoufallou, Richard J. Hartley, and Panorea Gaitanou, 424–436. Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-24129-6_37
- de Waal, Cornelis. 2013. Peirce: A Guide for the Perplexed. Guides for the Perplexed. London: Bloomsbury Publishing.
- Fleischhacker, David, Wolfgang Thomas Göderle, and Roman Kern. 2025. “Text Extraction for Complex Historical Documents: A Modular Approach to Layout Detection and OCR.” In Proceedings of the 24th ACM/IEEE Joint Conference on Digital Libraries, 1–3. New York: Association for Computing Machinery. https://doi.org/10.1145/3677389.3702524
- Garcia, Noa, and George Vogiatzis. 2019. “How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval.” In Computer Vision – ECCV 2018 Workshops, edited by Stefan Roth and Laura Leal-Taixé, vol. 11130, 676–691. Lecture Notes in Computer Science. Springer. https://doi.org/10.1007/978-3-030-11012-3_52
- Haider, Emman, Daniel Perez-Becker, Thomas Portet, Piyush Madan, Amit Garg, Atabak Ashfaq, David Majercak, et al. 2024. “Phi-3 Safety Post-Training: Aligning Language Models with a ‘Break-Fix’ Cycle.” arXiv:2407.13833. https://doi.org/10.48550/arXiv.2407.13833
- Hamburger, Jeffrey F. 2019. Diagramming Devotion: Berthold of Nuremberg’s Transformation of Hrabanus Maurus’s Poems in Praise of the Cross. Chicago: University of Chicago Press. https://doi.org/10.7208/chicago/9780226642956.001.0001
- Harvard University. 2023. “Charles S. Peirce Papers.” Accessed April 4, 2025. https://hollisarchives.lib.harvard.edu/repositories/24/resources/6437
- Hessel, Jack, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. 2021. “CLIPScore: A Reference-Free Evaluation Metric for Image Captioning.” arXiv:2104.08718. https://doi.org/10.48550/ARXIV.2104.08718
- Hou, Yifan, Buse Giledereli, Yilei Tu, and Mrinmaya Sachan. 2024. “Do Vision-Language Models Really Understand Visual Language?” arXiv:2410.00193. https://doi.org/10.48550/ARXIV.2410.00193
- Keeler, Mary. 1998. “Iconic Indeterminacy and Human Creativity in C. S. Peirce’s Manuscripts.” In The Iconic Page in Manuscript and Digital Culture, edited by George Bornstein and Theresa L. Tinkle, 157–194. Ann Arbor: University of Michigan Press.
- Keeler, Mary. 2020a. “Pragmatically Improving Access to Peirce’s Archive.” Chinese Semiotic Studies 16 (1): 167–187. https://doi.org/10.1515/css-2020-0009
- Keeler, Mary. 2020b. “The Hidden Treasure of C. S. Peirce’s Manuscripts.” Chinese Semiotic Studies 16 (1): 155–166. https://doi.org/10.1515/css-2020-0008
- Kiryushchenko, Vitaly. 2023. Diagrams, Visual Imagination, and Continuity in Peirce’s Philosophy of Mathematics. Mathematics in Mind. Cham: Springer International Publishing.
- Latour, Bruno. 1990. “Visualisation and Cognition: Drawing Things Together.” In Knowledge and Society: Studies in the Sociology of Culture Past and Present, edited by Henrika Kuklick, vol. 6, 1–40. JAI Press.
- Liang, Yichi, et al. 2024. “FlowLearn: A Modular Framework for Diagram Understanding.” arXiv:2412.16420v1.
- Liu, Haotian, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. “Visual Instruction Tuning.” arXiv:2304.08485. https://doi.org/10.48550/arXiv.2304.08485
- Pedretti, Carlo Teo, Maria Francesca Bocchi, Francesca Tomasi, and Fabio Vitali. 2024. “What Do We Annotate When We Annotate? Towards a Multi-Level Approach to Semantic Annotations.” In Knowledge Graphs in the Age of Language Models and Neuro-Symbolic AI, edited by Angelo A. Salatino, Mehwish Alam, Femke Ongenae, Sahar Vahdati, Anna Lisa Gentile, Tassilo Pellegrini, and S. Jiang, vol. 60, 370–385. Studies on the Semantic Web. Amsterdam: IOS Press. https://doi.org/10.3233/SSW240030
- Peirce, Charles S. 1931. Collected Papers of Charles Sanders Peirce, Vols. 1–6. Edited by Charles Hartshorne and Paul Weiss. Cambridge, MA: Harvard University Press.
- Picca, Davide, Aurélie Schnyder, Ekaterina Kostina, Anastasia Adamou, Dario Rodighiero, and Jeffrey Schnapp. 2023. “Orchestrating Cultural Heritage: Exploring the Automated Analysis and Organization of Charles S. Peirce’s PAP Manuscript.” In Proceedings of the 34th ACM Conference on Hypertext and Social Media (HT ’23), 1–4. Rome: Association for Computing Machinery. https://doi.org/10.1145/3603163.3609066
- Ravichandra, S., S. Siva Sathya, and L. Sophie. 2022. “Deep Learning Based Document Layout Analysis on Historical Documents.” In Advances in Distributed Computing and Machine Learning, 73–85. Singapore: Springer. https://doi.org/10.1007/978-981-16-9465-1_8
- Riva, Pat, Maja Žumer, and Trond Aalberg. 2022. “LRMoo, a High-Level Model in an Object-Oriented Framework.” IFLA. https://repository.ifla.org/handle/20.500.14598/2217
- Robin, Richard S. 1971. “The Peirce Papers: A Supplementary Catalogue.” Transactions of the Charles S. Peirce Society 7 (1): 37–57.
- Rodighiero, Dario, Alberto Romele, José Higuera Rubio, Celeste Pedro, Matteo Azzi, and Giorgio Uboldi. 2023. “Advanced Interface Design for IIIF: A Digital Tool to Explore Image Collections at Different Scales.” Umanistica Digitale 15: 167–192. https://doi.org/10.6092/ISSN.2532-8816/17230
- Sanderson, Robert, Paolo Ciccarese, and Benjamin Young. 2017. “Web Annotation Data Model.” W3C Recommendation. https://www.w3.org/TR/annotation-model/
- Stjernfelt, Frederik. 2007. Diagrammatology: An Investigation on the Borderlines of Phenomenology, Ontology, and Semiotics. Vol. 336. Synthese Library. Dordrecht: Springer Netherlands. https://doi.org/10.1007/978-1-4020-5652-9
- Yaseen, Muhammad. 2024. “What Is YOLOv8: An In-Depth Exploration of the Internal Features of the Next-Generation Object Detector.” arXiv:2408.15857. https://doi.org/10.48550/arXiv.2408.15857
- Zhang, Ruohong, Bowen Zhang, Yanghao Li, Haotian Zhang, Zhiqing Sun, Zhe Gan, Yinfei Yang, Ruoming Pang, and Yiming Yang. 2024. “Improve Vision Language Model Chain-of-Thought Reasoning.” arXiv:2410.16198.
- Zhu, Deyao, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. “MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models.” arXiv:2304.10592. https://doi.org/10.48550/arXiv.2304.10592
-
The models and the scripts used for the preprocessing and evaluation are available at https://anonymous.4open.science/r/PIP-Manuscripts-Processor-0147/. ↩
-
The dataset and RDF serializations are available at https://doi.org/10.5281/zenodo.16113285. ↩